Messaging allows software applications to connect and scale. Different applications can connect to each other, as components of a larger application through messaging.
You might be thinking, how this messaging between different applications can be actually achieved and what is the best way of exchanging data between processes, applications, and servers?
Well, if you ask me then the answer is “RabbitMQâ€.
RabbitMQ is open source message broker software. The principal idea is pretty simple: it accepts and forwards messages.
RabbitMQ is the most popular open-source implementation of the AMQP (Advanced Message Queuing Protocol) messaging protocol, written in “Erlang†that you can access from any language.
It is software where queues are defined; application binds and listens to these queues and transfer messages from it.
Basic architecture of a message broker is simple, there are client applications called producers that create messages and deliver them to the broker. Other applications, called consumers, connects to the queue, subscribes and gets the messages. Software can be either a producer, or consumer, or both. Messages placed onto the queue are stored until the consumer retrieves them.
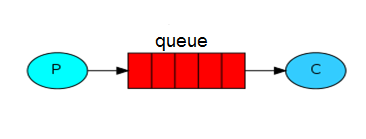
Where,
- P – Producer, sends message to queue
- C – Consumer, waits to receive messages from queue
- queue – Queue (Message Broker)
A queue is the name for a mailbox. It lives inside RabbitMQ, although messages flowing through RabbitMQ and your applications can be stored only inside a queue. There is no limit for the queue; it can store as many messages as you want. Essentially it’s an infinite buffer. You can have many producers to send messages to one queue or many consumers can try to receive data from one queue.
Ideally, producer, consumer, and broker don’t have to reside on the same machine; however in most applications they don’t.
In order to make sure that, messages from producers go to right consumer, RabbitMQ broker uses two key components: Exchanges and Queues
So, just to be clear, messages in RabbitMQ are not published directly to queue, instead producer sends message to an entity called “Exchangeâ€. Exchanges are like message routing agents.
Below diagram will help you to understand, where these entities stands in RabbitMQ:
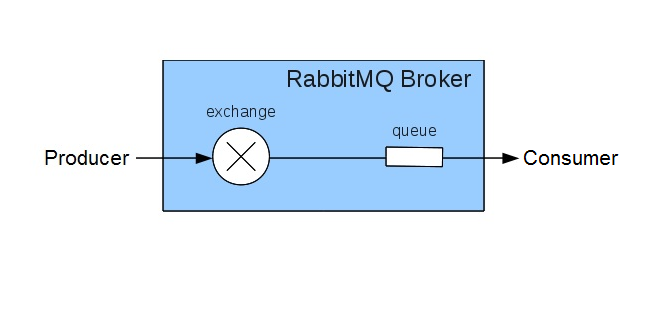
The exchange is responsible for the routing the messages to the different queues. An exchange accepts messages from the producer application and routes them to message queues with the help of bindings and routing keys. A binding is the link between a queue and an exchange.
Ideally, RabbitMQ server setup contains multiple queues (one per consumer) as follow:
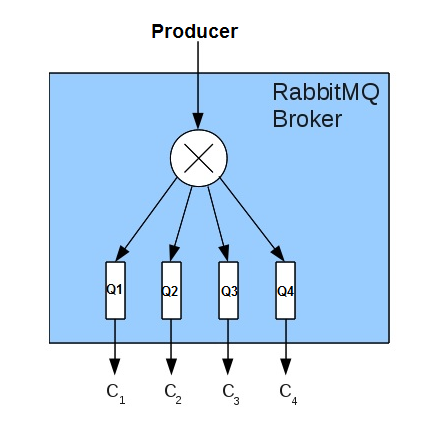
Here, C1, C2, C3, C4 are consumers, Q1, Q2, Q3, Q4 – are queue names which are bind with C1, C2, C3, C4 respectively.
We can also have more than one exchange and with different name in single RabbitMQ setup. Usually, the publisher or consumer creates the exchange with a given name and then send it to known clients.
Now, you might be thinking of how messages actually routed from exchange to appropriate queue?
First, a consumer/producer (typically consumer) creates a queue and attaches it to an exchange with a specific routing key. This process is called as binding.
Basically, each queue is attached with exchange with different routing key.
Before understanding further flow, we need to understand structure of an AMQP message:
Each message sent through RabbitMQ is having following format-

First two fields, the headers and properties of the message are basically key/value pairs.
- Headers – Defined by the AMQP specification
- Properties – Contain application-specific information.
- Bytes [] data – Actual message content.
Now, as you have understood the RMQ message structure, let’s come back to binding concept.
Each message header contains “routing-keyâ€. This routing key is used to identify its appropriate queue. Each consumer keeps listening on queue and these queues are attached to Exchange with specific binding key.
So whenever exchange gets message from producer, message broker finds “routing-key†from message header and compares with each queue’s binding key. And finally message is sent to queue which matches its binding key with message header “routing-keyâ€. And respective consumer who is listening to this queue gets message and starts processing. That’s it J
There are 4 types of exchanges based on, how binding key matches with routing key.
| Sr.No. | Exchange Type | Behavior |
| 1 | Direct Exchange | The binding key must match the routing key exactly – no wildcard support |
| 2 | Topic Exchange | Same as Direct, but wildcards are allowed in the binding key. ‘#’ matches zero or more dot-delimited words |
| 3 | Fanout Exchange | The routing and binding keys are ignored – all published messages go to all bound queues. |
| 4 | Header Exchange | Headers exchanges use the message header attributes for routing. |
You can install the RabbitMQ on your host machine and play with its management UI webpage using link- “https://<host-ip>:555672â€
<host-ip> is the one where you have installed RabbitMq client.
At the last, let me tell you few reasons that will probably make RabbitMQ best choice-
- Decoupling: One of the main requirements for software development is to have decoupled components in it. This can be easily done using RabbitMQ.
- Scalability: By using RabbitMQ, we can allow producer to transmit a message/task/command for processing to unlimited number of consumers. Before this make sure that, you have already created new message consumers.
- Flexibility: Using RabbitMQ (which uses AMQP protocol), we can easily connect or allow to communicate two totally different applications (can be written on different languages) together.
- Many Clients: There are RabbitMQ client’s supports for almost any language you can think of.
[Tweet “RabbitMQ – Robust Way of Messaging for Application ~ via @CalsoftInc”]





