First, there were specialized hardware – Gateways, Routers, Switches and Firewalls. People used hard manual labour to move them from one place to another ie: from a manufacturer to their data center.
There used to be updates to firmware every now and then, for patching vulnerabilities. New H/w was always at the “receiving gate” of the data center, ready to be deployed. This used to take all of the network administrator’s day time, and of course, night time used to be reserved for usual network issues and emergencies. Thus a network administrator was the best performing employee of the company, every single month. These devices were fast, so end users were also happy!
Then there was an idea to load the network functionality from these vendor specific locked-in architecture devices on to a COTS (commercial off the shelf) server, which you can buy on amazon. That solved the problem partially – the upfront costs of buying network gear. It also provided good scalability in terms of upscaling the H/w as and when needed, resulting in increased capacity for new requests. Overall costs were reduced for both the IT department and CEOs were happy to show better profit margins. However, the end users were not happy, as they found their requests for network resources were taking longer.
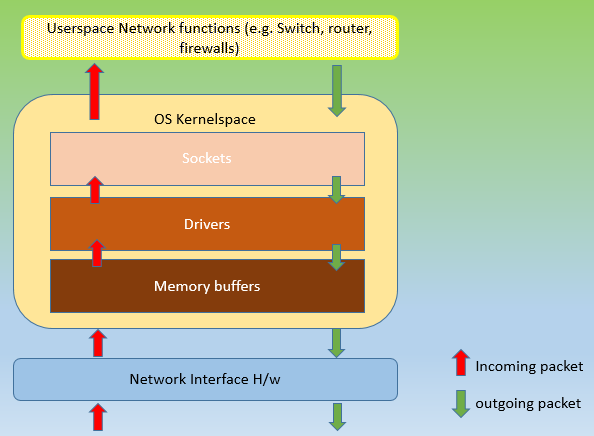
Traditionally, hardware which were RISC based computing systems, with the firmware tailored to operate on them, was very efficient, and the operations were fast! COTS based systems ran known flavors of Linux OS, and network functionality provided by software applications running on them. Every operation needed to be performed on network packets, had to be routed and tracked through entire OS(kernel) and Application(userspace) stack. This is red-tapism in the software world, every agency taking its sweet time for decision making. Following every rule and regulation in the book, serving everything but the purpose it was supposed to be there for.
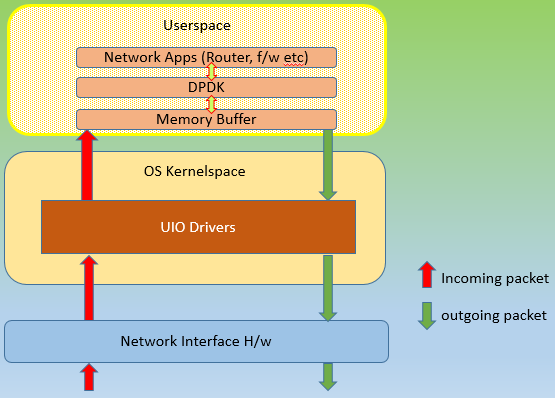
DPDKÂ (Data Plane Development Kit) came along. It said, “from today on wards there is going to be just one agency, itself, following just one rule book, a dpdk library“, irrespective of what the requestor’s end goal is.
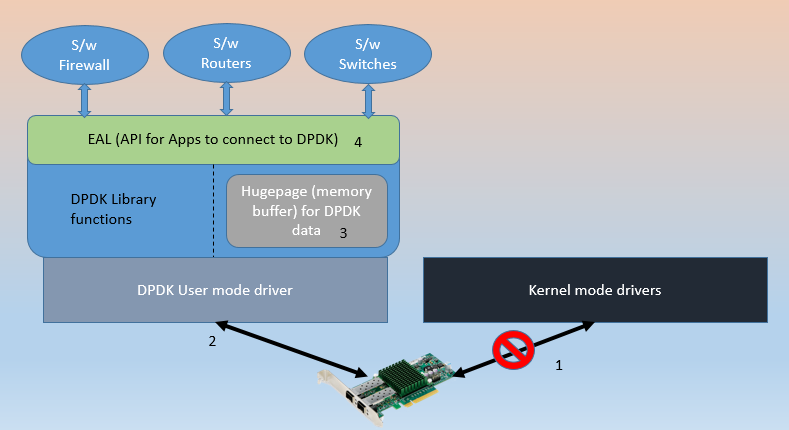
All packets, needing network functionality processing (again, it means routing, switching, firewall allow/deny etc), had to be routed through it, and it would green-channelize them all. It would not call upon the kernel actions for processing these requests, and hence no system called. It promised to accelerate the network functions by a large margin. And it did!
How was it done? It is but logical, that if most things could be processed within userspace, network packets could be spared of, bottlenecks within Linux OS kernel stack. There had to be large changes to how a network card could be called upon to do any work.
- First they had be freed of kernel’s absolute control over it.
- A user mode driver, part of dpdk was brought in.
- A userspace memory buffer was enabled so that all the ‘in-process’ data used by dpdk could be stored.
- An interface, EAL, ‘Environment Abstraction Layer’ was created for Applications (switches, routers, firewalls etc.) to talk to dpdk.
Advantages of DPDK include everything that comes out of software based network function deployments (low cost of ownership, scalability, upgrade considerations etc) + a huge performance boost.
A solution that I have seen very recently, piqued my interest to investigate and write about DPDK. This particular case relates to an implementation of a virtual router:
NFV: Virtual router based on DPDK: Here performance boost recorded was whopping 3x the Linux only implementation. This was tested by using DPDK-pktgen to generate a 64 bit UDP packets using random source and destination IPs, with 4, Rx queues.
If you want to know more how these nitty gritties were handled, connect with us.
[Tweet “DPDK in 3 minutes or Less… ~ via @CalsoftInc”]






Although, author has provided good enough pictures on the topic but I guess a little more explanation is needed.
yes. Mandar is planning to write more in depth articles on DPDK. Stay tuned to our blog.
i had a basic question on implementing a software-based Switch/Router function (L2/L3 based). Normal switch/routers from the likes of Cisco/Juniper have N physical ports. So for a NFV-implemented router will we be using N NIC ports?
For an NFV implemented routers, physical NICs only receive and transmit (ingress & egress) the packets meant for processing. As such all such NICs would be part of NFV solution. The point to note here is, it is not enough to just have multiple NICs under NFV solution, it must also accompany processing capabilities. Typically this is achieved by setting processor core affinity to process packets for that NIC. E.g. 4 NIC NFV router should have a CPU with 4+ cores. Each core for dedicated processing of traffic on each NIC.
Thank you!
Mandar Shukla